Test-time Scaling
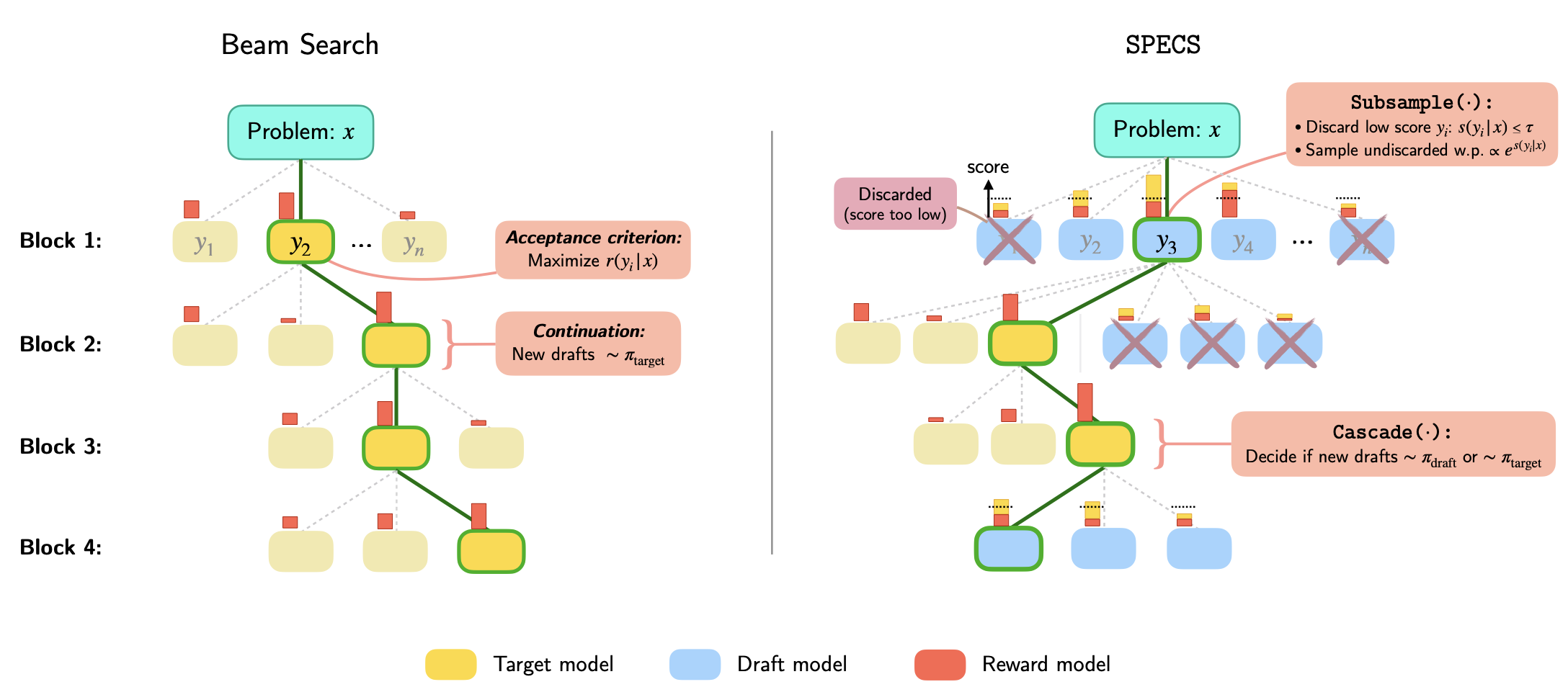 |
While scaling up computation at test-time improves the reasoning abilities of LLMs, it often leads to higher latency, which negatively impacts the user experience. Current methods typically focus on optimizing for accuracy based on computational resources, neglecting the crucial aspect of latency. SPECS tackles this problem by using a smaller, faster model to generate candidate sequences, which are then evaluated by a larger, more powerful model and a reward model. This approach, inspired by speculative decoding, incorporates new strategies like reward-guided soft verification and a reward-based deferral mechanism to decide which model to use for subsequent steps. The paper demonstrates that SPECS can achieve comparable or even better accuracy than existing methods like beam search, while significantly reducing latency by up to 19.1% on various math reasoning benchmarks.
Publications
M. Cemri, et al., “SPECS: Faster Test-Time Scaling through Speculative Drafts”, ICML Workshop 2024.